
ARM Announces Project Trillium Machine Learning IPs
![]()
Today’s Arm announcement is a bit out of the norm for the company, as it’s the first in a series of staggered releases of information. For this first announcement Arm is publicly unveiling “Project Trillium” – a group of software solutions as well IP for object detection and machine learning.
Machine learning is indeed the hot new topic in the semiconductor business and has particularly seen a large focus in the mobile world over the last couple of months, with announcements from various IP companies as well as consumer solutions from the likes of Huawei. We’ve most recently had a more in-depth look and exploration of the topic of machine learning and neural network processing in a dedicated section of our review of the Kirin 970.
Whilst we had a great amount of noise from many industry players on the topic of machine learning IPs. Arm was conspicuously absent from the news and until now the focus has been on the CPU ISA extensions of Armv8.2, which introduce specialised instructions which simplify and accelerate implementations of neural networks with the help of half-precision floating point and integer dot products.
Alongside the CPU improvements we've also seen GPU improvements for machine learning in the G72. While both of these improvements help, they are insufficient in use-cases where maximum performance and efficiency are required. For example, as we’ve seen in the our test of the Kirin 970’s NPU and Qualcomm’s DSP – the efficiency of running inferencing on specialized IPs is above an order of magnitude higher than running it on a CPU.
As Arm explains it, the Armv8.2 and GPU improvements were only the first results towards establishing solutions for machine learning, while in parallel they’ve examined the need for dedicated solutions. Industry pressure from partners made it clear that the performance and efficiency requirements made dedicated solutions inevitable and started work on its machine learning (ML) processors.
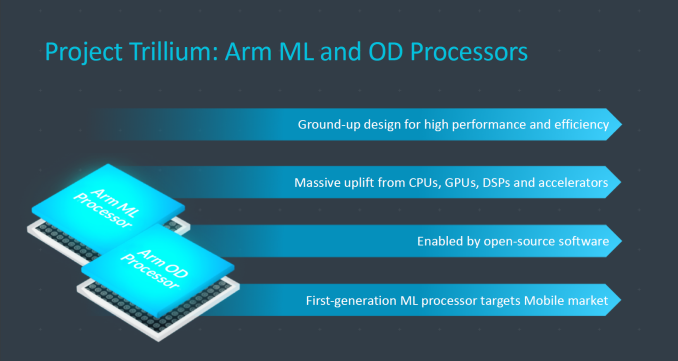
Today’s announcement covers the new ML processors as well as object detection processors (OD). The latter IP is a result of Arm’s Apical acquirement in 2016 which saw the company add solutions for the display and camera pipelines to their IP portfolio.
Starting with the ML processor – what we’re talking about here is a dedicated IP for neural network model inferencing acceleration. As we’ve emphasised in our NN related announcements of late, Arm also emphasises that having an architecture which is specifically designed for such workloads can have significant advantages over traditional CPU and GPU architectures. Arm also made a great focus on the need to design an architecture which is able to do optimised memory management of the data that flows through a processor when executing ML workloads. These workloads have high data reusability and minimising the in- and out-bound data through the processor is a key aspect of reaching high performance and high efficiency.

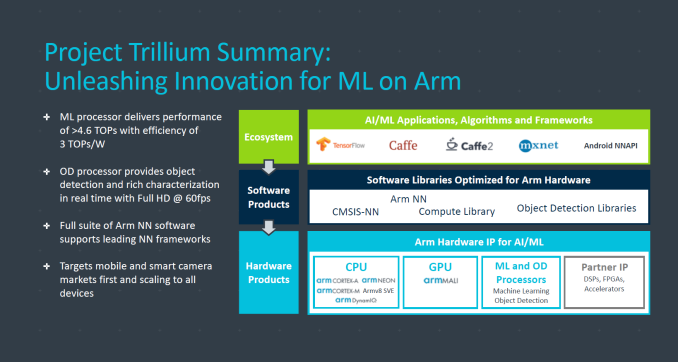
Arm’s ML processor promises to reach theoretical throughput of over 4.6TOPs (8-bit integer) at target power envelopes of around 1.5W, advertising up to 3TOPs/W. The power and efficiency estimates are based on a 7nm implementation of the IP.
In regards to the performance figures, Arm agrees with me that the TOPs figure alone might not be the best figure to represent performance of an IP; however it’s still useful until the industry can work towards some sort of standardisation for benchmarking on popular neural network models. The ML processor can act as a fully dedicated and standalone IP block with its own ACE-Lite interface for incorporation into a SoC, or it can be integrated within DynamiQ cluster, which is a lot more novel in terms of implementation. Arm wasn’t ready to disclose more architectural information of the processor and reserves that for future announcements.
An aspect that seemed confusing is Arm’s naming of the new IP. Indeed Arm doesn’t see that the term “accelerator” is appropriate here as traditionally accelerators for Arm meant things such as packet handling accelerators in the networking space. Instead Arm sees the new ML processor as a more fully-fledged processor and therefore deserving of that naming.

The OD processor is a more traditional vision processor and is optimised for the task of object detection. There is still a need for such IP as while the ML processor could do the same task via neural networks, the OD processor can do it faster and more efficiently. This showcases just how far the industry is going to make dedicated IP for extremely specialised tasks to be able to extract the maximum amount of efficiency.
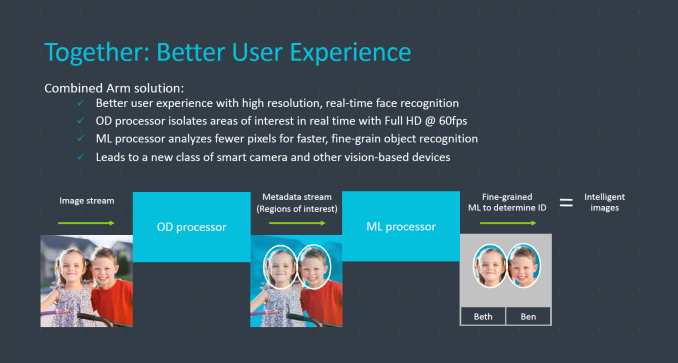
Arm envisions use-cases where the OD and ML processors are integrated together, where the OD processor would isolate areas of interest within an image and forward them to the ML processor where more fine-grained processing is executed on. Arm had a slew of fun examples as ideas, but frankly we still don’t know for sure how use-cases in the mobile space will evolve. The same can’t be said about camera and surveillance systems where we see the opportunity and need for continuous use of OD and ML processing.
Arm’s first generation of ML processors is targeted at mobile use while variants for other spaces will follow on in the future. The architecture of the IP is said to be scalable both upwards and downwards from the initial mobile release.
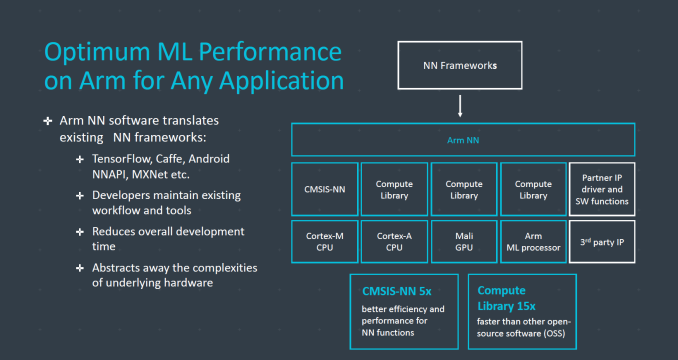
As part of Project Trillium, Arm also makes available a large amount of software that will help developers implement their neural network models into different NN frameworks. These are going to be available starting today on Arm’s developer website as well as Github.
The OD processor is targeted for release to partners in Q1 while the ML processor is said to be ready mid 2018. Again this is highly unusual for Arm as usually public announcements happen far after IP availability to customers. Due to the nature of SoC development we should thus not expect silicon based on the new IP until mid to late 2019 at the earliest, making Arm one of the slow-adopters among the semiconductor IP vendors who offer ML IP.