

Qualcomm Details Hexagon 680 DSP in Snapdragon 820: Accelerated Imaging

Although we tend not to focus too much on the tertiary aspects of a SoC, they are often important to enabling many aspects of the user experience. DSPs are important for a number of unique applications such as voice processing, audio processing, and other input processing applications. Before we get into the meat of the article though it's important to note that the above image is not a die shot or an actual block diagram, but is very roughly approximating the relative size of each component in the SoC.
Today at Hot Chips, Qualcomm elected to reveal a number of details about their Hexagon 680 DSP, which will ship in the Snapdragon 820. Those that have followed our coverage regarding the Snapdragon 820 ISP features will probably be able to guess that a number of features on the Snapdragon 820 Spectra ISP are enabled through the use of this newer DSP.

For those that are unfamiliar with DSPs, the basic idea behind DSPs is that they are a sort of in-between point in architecture design between highly efficient fixed function hardware (think: video decoders) and highly flexible CPUs. DSPs are programmable, but are rigid in design and are designed to do a limited number of tasks well, making them efficient at those tasks relative to a CPU, but more flexible than fixed function hardware. These design goals are typically manifested in DSPs as in-order architectures, which means that there's much less power and area dedicated on silicon to parallelize code on the fly. This means that while a DSP can do a number of workloads that would otherwise be impossible on a completely fixed-function block, you wouldn't want to try and use one to replace a CPU. It's important to emphasize that DSPs are generally more focused on instruction-level parallelism (single core performance) rather than thread-level parallelism (multi-core performance), so you won't see hundreds/thousands of "cores" in a DSP like you would in a GPU architecture like Maxwell.
Consequently the architecture of DSPs like the Hexagon 680 are relatively alien compared to standard CPUs, as optimization is everything in the applications where DSPs make sense. For example, DSP instruction sets are often VLIW (very long instruction word), in which multiple execution units are driven in parallel with a single instruction. Certain arithmetic operations are also highly accelerated with special instructions in order to enable key algorithms for signal processing such as Fast Fourier Transform (FFT).

In the case of the Hexagon 680, one of the key features Qualcomm is focusing on for this launch are Hexagon Vector Extensions (HVX). HVX is designed to handle significant compute workloads for image processing applications such as virtual reality, augmented reality, image processing, video processing, and computer vision. This means that tasks that might otherwise be running on a relatively power hungry CPU or GPU can run a comparatively efficient DSP instead.

The HVX extension to Hexagon has 1024-bit vector data registers, with the ability to address up to four of these slots per instruction, which allows for up to 4096 bits per cycle. It's important to keep in mind that the instruction width is much smaller than this as this is a single instruction, multiple data (SIMD) unit which uses one operation over multiple chunks of data. There are 32 of these vector registers, which appear to be split between two HVX contexts. There is support for up to 32 bit fixed point decimal operations, but floating point is not supported to reduce die size and power consumption, as the previously mentioned applications for Hexagon 680 don’t need floating point support. As DSPs tend to have ISAs tailored for the application, the Hexagon 680 HVX units support sliding window filters, LUTs, and histogram acceleration at the ISA level. The performance of these units are said to be sufficient for 4K video post-processing, 20MP camera burst processing, and other applications with similar compute requirements.

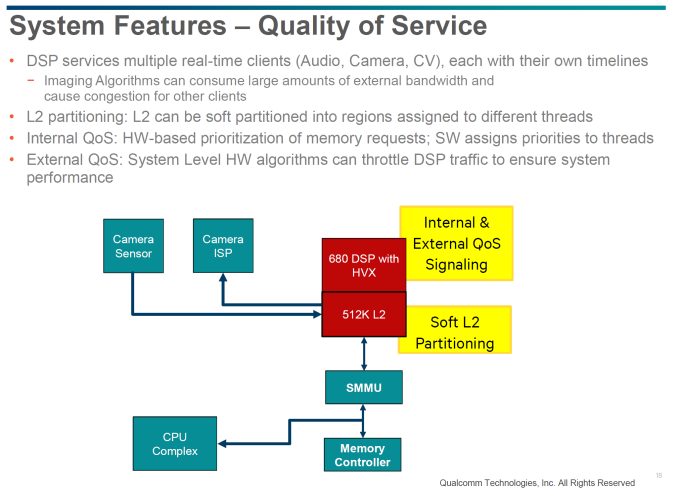
Outside of these details at a per-context basis, the threading model and memory hierarchy of the Hexagon 680 is quite unique. For scalar instructions, four threads are available with a 4-way VLIW architecture running at 500 MHz per thread. These scalar units all share an L1 instruction cache, L1 data cache, and L2 cache. The two HVX contexts in the Hexagon 680 can be controlled by any two scalar threads and also run at 500 MHz without stalling other scalar units not involved in controlling the vector units. This level of hardware-level multithreading along with QoS systems and L2 soft partitioning on a per-thread helps to make sure audio and imaging tasks aren’t fighting for execution time on the Hexagon DSP.


Meanwhile the vector units are fed exclusively from the L2 cache that is shared with the scalar units, a choice Qualcomm made due to the overhead that comes with an L1 cache for image processing workloads. This L2 cache can do load to use in a single cycle though, so one could argue that this is technically an L1 cache at times anyhow. The Hexagon 680 in the Snapdragon 820 will also be able to have data from the camera sensor directly streamed to the L2 cache and shared with the ISP to avoid the power cost of going off-die to DRAM. There’s also an SMMU (System Memory Management Unit) which allows for no-copy data sharing with the CPU for multiple simultaneous applications. DSP memory writes will also snoop-invalidate CPU cache without the need for the CPU to do any work involving cache maintenance to reduce power consumption and improve performance.


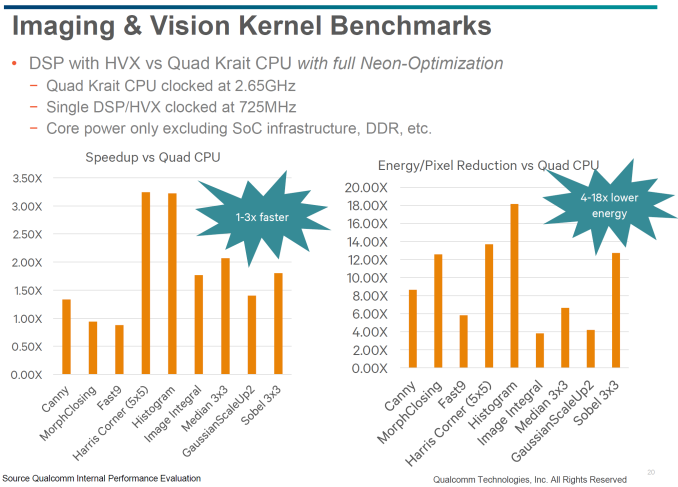
Relative to a quad-core Krait, the advantages of running some workloads on a DSP is enormous based on Qualcomm's internal benchmarks. According to Qualcomm, the NEON units in the Krait CPU are generally representative of NEON units within the industry, which is the reason why they've been used as the reference point here. Within a single logical “core”, Krait will only support 128-bit NEON with a single SIMD pipeline, compared to the 4-way, 1024-bit SIMD units of the Hexagon 680. SIMD threads also run on a 512KB L2-but-almost-L1 cache, as opposed to the 32KB L1 instruction/data cache of Krait, which helps to hide latency effects of DRAM. The NEON units of a Krait and many other ARM CPUs are capable of floating point, but in a workload like low light video enhancement Hexagon 680 will be able to complete the same amount of work at three times the speed, while using an order of magnitude less power due to the inherent advantages of a task-specific DSP architecture. The four scalar threads available in the DSP also means that entire algorithms can be off-loaded to the DSP instead of partially running on the CPU, which also reduces power consumption and makes it easier for developers to take advantage of the DSP.

While Hexagon 680’s vector and scalar engines are useful for heavy-duty signal processing workloads, the addition of the low power island (LPI) DSP makes it possible to do away with separate sensor hubs in smartphones. According to Qualcomm, this DSP is completely separate from the scalar and vector compute DSP previously discussed (yet still part of the overall Hexagon DSP design), and sits on its own power island so the rest of the SoC can be shut down while keeping the LPI on. This also shouldn’t have a different process technology or a radically different standard cell library, as the advantages from the leading edge FinFET process should help significantly with power consumption.


It’s said that this low power island with an independent DSP and newer process node is enough to improve power efficiency by up to three times in certain workloads compared to Snapdragon 808. I suspect that this was done instead of a comparison to the MSM8974/Snapdragon 800 generation because the Hexagon DSP was updated in the move from Snapdragon 805 to 808. Qualcomm emphasized the choice of a DSP over an MCU for this task, as in their internal testing a DSP delivers better power efficiency than a Cortex M-class MCU for more advanced sensor algorithms. The software stack for all of these features is already said to be quite complete, with a framework and algorithms included for OEM development. The broader Hexagon 600 series SDK is also quite extensive, with a number of utilities to allow for faster and easier development.
If you’re like me, after going through all of this information you might be wondering what the value of these vector DSP extensions are. In discussions with Qualcomm, it seems that the reasoning behind pushing a number of image processing tasks to the Hexagon DSP core is mostly because the algorithms behind things such as HDR video, HDR image merging, low light image enhancement, and other advanced algorithms are still in flux even from software update to software update. As a result, it isn’t viable to make these aspects of the imaging pipeline done in fixed-function hardware. Without the use of the Hexagon DSP, these tasks could potentially end up running on the CPU or GPU, affecting user experience in the form of higher shot to shot latency, reduced battery life when using the camera, and higher skin temperatures. It remains to be seen whether OEMs using Snapdragon 820 will use these DSPs to the fullest extent, but the Snapdragon 820 is shaping up to be a promising 2016 high-end SoC.